

Назъров
-
Общо Съдържание
32 -
Дата на Регистрация
-
Последно Посещение
Съдържание Тип
Профили
Форуми
Блогове
Статии
Молитви от Учителя
Музика от Учителя
Мисли
Галерия
Каталог Книги
За Теглене
Videos
Мнения добавени от Назъров
-
-
Има и друг начин - да се изтрият всички "бисквитки" от домейна beinsadouno.com. Например за Firefox, от менюто се избира Tools\Options, избира се бутон "Show cookies", в реда за търсене се пише "beinsa", маркират се всички намерени "бисквитки" и се изтриват. След това вече може да се влезе в портала. Мисля, че проблемът е свързан с кода на портала за запаметяване на паролата.
-
В сканирания текст много често пред изречения има "чавка". Понякога е разпозната като символ, друг път - не. Отбелязвам я в червено, така: <font color="red">></font>. Но се налага много често да го правя и затрупвам текста с излишни знаци. Какво правите в този случай?
Според мен тези чавки са дефекти от печата и аз просто ги премахвам.
-
Вярно. TinyMCE обаче има бутонче "Paste From Word". Не знам дали има някаква конкретна полза от него.
Във FCKeditor има същото бутонче и май работи по-добре от TinyMCE.
-
-
Ето някои модули за Drupal, коита са потенциално използваеми за нашите цели:
http://drupal.org/project/computed_field
http://drupal.org/project/contemplate
http://drupal.org/project/date
http://drupal.org/project/easy_image_insert
http://drupal.org/project/email
http://drupal.org/project/imagefield
http://drupal.org/project/linodef
http://drupal.org/project/link
http://drupal.org/project/unique_field
http://drupal.org/project/validation_api
http://drupal.org/project/workflow_fields
http://drupal.org/project/advanced_forum
http://drupal.org/project/archive_by_terms
http://drupal.org/project/photos
http://drupal.org/project/book_copy
http://drupal.org/project/book_manager
http://drupal.org/project/category
http://drupal.org/project/checkout
http://drupal.org/project/comment_subscribe
http://drupal.org/project/dbfm
http://drupal.org/project/dataset
http://drupal.org/project/draft
-
В рамките на текущият проект нашето внимание е насочено само към беседите. Звучи разумно обхватът на схемата на кодификация да бъде разширен, но това няма как да се случи в рамките на проекта.
Васко,
Нали твоя беше идеята, издателството също да възприеме тази кодификация в своите издания? Тоест, тази система за кодифициране надхвърля границите на текущия проект, и единствено поради този факт аз виждам някакъв смисъл в нейното основаване. В тесните рамки на електронния архив с беседите и каталозите към него, това кодифициране е напълно излишно, защото там то представлява просто една справка върху съществуващата базова информация. Защо трябва да изпишем толкова думи, само за да спестим 2 байта от кодификацията, липсата на които би обезсмислило самото й съществувание?
-
А вместо да се изписва цялата година,не е ли по-удачно да се изпишат само последните две цифри на година - за 1922 - само 22!?
Не е по-удачно, защото Учителят е творил и през 19-ти и през 20-ти век. А ако използваме същия принцип за кодифициране и за каталога с материали "за Учителя", тогава ще имаме и 21-и век. Вече имахме "проблем 2000", нека не си създаваме и "проблем 1800".
-
Да, всъщност кодът за беседите би улеснил цитирането, референцията към беседа. И то предимно в статии, в съдържания.
Добре, съгласен съм, но за мен много по-естествен е код, който съдържа година, месец, ден и час. Това е напълно достатъчно, за да се идентифицира уникално всяка беседа и е същевременно напълно разбираемо за "невъоръжено" човешко око. Евентуално, може да се добави и една буква за вида на беседата, с чисто справочна цел. Така, в базата ще се съхранява: "1922032605Б", а при извеждане може да се показва: "1922.03.26:05-Б".
Всъщност, в базата тази информация така или иначе се съхранява по друг начин, тъй че този код не е нужно да се пази като отделно поле, а може винаги да бъде синтезиран и ръчно и автоматично при нужда. Автоматично, това синтезиране може да става както с SQL, така и с програмна логика.
-
Между другото, имайки пред себе си каталога на произведенията на Р.Щайнер, мисля че можем да взаимстваме нещо от него - например номерирането им - всяко призведение има номер, тъй като и неговата работа е доста обемиста, затова създателите на каталога са решили, че се налага въвеждането на номерация, която е постоянна.
Аз не виждам, какво можем да заимстваме от каталога на творчеството на Рудолф Щайнер. В този каталог лекциите са структурирани в лекционни цикли, като всеки цикъл се състои от определен брой лекции, разглеждащи една обща централна тема. Лекциите от един цикъл са смислово и тематично свързани последователно, въпреки че често всички лекции от даден цикъл са били изнасяни в различни европейски градове. В този каталог библиографски са номерирани само циклите и книгите, а не отделните лекции.
Единственото общо (от библиографска гледна точка) между лекциите на Рудолф Щайнер и беседите на Беинса Дуно е, че и едните и другите имат дата, час и място на изнасяне и обикновено имат и заглавие. Оттук нататък класификационните и структуроопределящите признаци са съвсем различни.
-
Приятели,
Тази кодификация е напълно възможна, но друг въпрос е доколко е необходима. Този вид кодифициране е измислен в миналото за организиране на ръчната работа с хартиени документи. В една компютърна информационна система този начин на кодифициране става напълно излишен и сега ще обясня защо. При съхраняването на беседите, като техни основни атрибути (наред с други) се съхраняват вид, дата и час на изнасяне. На базата на тази информация, въпросната кодификация може да бъде автоматично генерирана от компютъра при необходимост. Тоест, кодификацията е просто още един начин за съхраняване на информация, който обаче е удобен за ръчна работа с хартиени документи, а при компютърната обработка представлява излишно дублиране на информацията. Също и излишен ръчен труд, да се кодифицира всяка беседа при въвеждането и в системата.
-
Здравейте, приятели!
След като изчетох всички съображения, които сте изказали до момента, мога да кажа, че единствената система, която съм видял до момента, която може бързо, лесно и гъвкаво да задоволи всички текущи изисквания, както и евентуалните бъдещи, това е Drupal. Уникалността на Drupal стои в следното:
1. Системата приема и съхранява всякакви видове информация - текстова, графична, мултимедийна и т.н., без ограничения.
2. Има специален модул в "сърцето" на системата, който позволява динамичното създаване на всякакви видове и структури каталози без ограничения. Така, съхраняваните информационни единици/масиви могат да бъдат включени/свързани във всякакви каталожни системи. Тук отпада въпросът, какви каталози може да бъдат направени и остават само въпросите, какви каталози искаме да направим и кой ще ги изгражда и поддържа.
3. Системата притежава собствен графичен уеб интерфейс, който позволява динамично дефиниране, генериране и изграждане на уебсайтове според нуждите.
4. Всичко дотук може да се направи без специално програмиране, само с измисляне, дефиниране, конфигуриране и въвеждане на информация, при това, само със стандартните възможности на Drupal. Все още не съм прегледал наличните допълнителни модули.
(Прегледах модула Marc, но предвид възможностите на Drupal, не мисля, че ще ни свърши работа. Същото важи и за всички други специализирани библиотечни и библиографски системи, които съм виждал - Drupal ги "надхвърля" многократно)
5. Системата сигурно има и ограничения и недостатъци, но аз все още не съм ги открил.


Всичко това не отменя нуждата от изготвяне на детайлен проект и функционална спецификация на това, което искаме да направим. И разбира се, няма причина докато "мъдрите се намъдруват", текущата работа в уикито да спира. Когато/ако успеем да направим нещо функционално с Drupal, много лесно ще прехвърлим нещата от уикито.
-
Ами, за да не дублираме работата си, аз вече инсталирах Drupal на един хостинг и започнах да структурирам в него видовете информация и начините за работа... Засега изглежда много обещаващо и категорично по-добре от Wikimedia.
Като съм се захванал с Drupal, ще проуча и този модул за Drupal - Marc.
Васко,
Този продукт - Greenstone - поразгледах го бегло и нещо не ме вдъхновява. Без да навлизам в подробности, Drupal ми изглежда доста по-подходящ за нашите цели. Разбира се, тези мои впечатления все още не са особено задълбочени, така че нямам никакви претенции за меродавност и окончателност.
-
не може ли на 1-во време да използваме някоя CMS (Moodle, Drupal и т.н., и т.н.)?
Аз нямам опит с CMS, но и на мен ми се струва, че там възможностите за организиране на нашата работа са доста по-големи. В момента съм инсталирал и разглеждам Drupal. Но както вече казах - нямам опит - и при това положение, за мен думите на Иво звучат много актуално: "Ако се наемаш да избереш уеб софтуер, да го инсталираш, промениш по подходящ начин, подготвиш за работа и поддържаш..."
-
Според мен ползването на Wiki като платформа на подобен каталог ще носи своите оганичения в бъдеще.
Според мен също, но на срещата във Варна преценихме, че на този етап не разполагаме с достатъчно ресурси, за да създадем специализирана информационна система. При това положение остава да ползваме наличните "подръчни" средства, за да организираме някак работата за обработка на неиздаденото слово. А когато един ден успеем да създадем и специализирана система, вече събраните текстове ще могат лесно да бъдат прехвърлени в нея.
Васко, ти би ли участвал в разработването на специализирана ИС?
-
Прегледах всички налични разширения тук и следните ми се сториха потенциално полезни за нашите цели:
http://www.mediawiki.org/wiki/Extension:AuthorProtect
http://www.mediawiki.org/wiki/Extension:Bibliography
http://www.mediawiki.org/wiki/Extension:Bibwiki
http://wiki-tools.com/wiki/Wiki_Category_Tag_Cloud
http://www.mediawiki.org/wiki/Extension:Cite
http://www.mediawiki.org/wiki/Extension:Collection
http://www.mediawiki.org/wiki/Extension:Configure
http://www.mediawiki.org/wiki/Extension:ConfirmAccount
http://www.mediawiki.org/wiki/Extension:CorporateContact
http://www.mediawiki.org/wiki/Extension:DiscussionThreading
http://www.mediawiki.org/wiki/Extension:DynamicPageList
http://www.mediawiki.org/wiki/Extension:EditUser
http://www.mediawiki.org/wiki/Extension:EditWarning
http://www.mediawiki.org/wiki/Extension:EmailAddressImage
http://www.mediawiki.org/wiki/Extension:FC...itor_and_Wikia)
http://www.mediawiki.org/wiki/Extension:Glossary
http://www.mediawiki.org/wiki/Extension:GroupPortal
http://www.mediawiki.org/wiki/Extension:Header_Footer
http://www.mediawiki.org/wiki/Extension:LiquidThreads
http://www.mediawiki.org/wiki/Extension:NewArticleTemplates
http://www.mediawiki.org/wiki/Extension:NewUserMessage
http://www.mediawiki.org/wiki/Extension:Newest_Pages
http://www.mediawiki.org/wiki/Extension:PDF_Writer
http://www.mediawiki.org/wiki/Extension:Pdf_Book
http://www.mediawiki.org/wiki/Extension:PreloadManager
http://www.mediawiki.org/wiki/Extension:Proofread_Page !!!
http://code.google.com/p/wikimediaspellchecker/ !!!
http://www.mediawiki.org/wiki/Extension:TransformChanges
http://www.mediawiki.org/wiki/Extension:Word2MediaWikiPlus
Сега ще започвам да ги инсталирам едно по едно и да ги тествам...
-
Здравей, Ани! (Хайде на "ти")
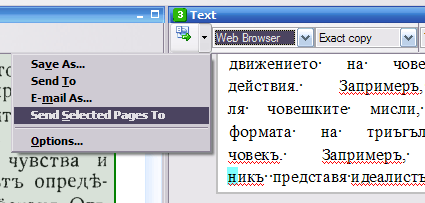
1. Ако се качи картинка/фигура и тя не е сполучлива, то може ли да се изтрие от базата данни или си остава там.Може да се изтрие или да се подмени с друга картинка.
2. Можете ли да опишете как става свалянето на фигурата от текста и оформянето ѝ в описаните формати: png, gif, jpg, jpeg.Ами може да стане по много начини, но ето един примерен, ако работиш с "ABBYY Fine Reader":

- От комбобокса избираш "Web Browser", както е показано на картинката и от бутончето в ляво избираш "Send...", също както е показано.
- Това трябва да отвори уеб браузър с текста на страницата и фигурите. Чуква се с десния бутон на мишката върху фигурата и се избира "Save Image As", след което фигурата се запазва като графичен файл.
- Ако е необходимо, запазеният графичен файл може да бъде допълнително обработен с редактор на растерни изображения, или може да бъде векторизиран и запазен като векторен файл с векторен редактор.
- От комбобокса избираш "Web Browser", както е показано на картинката и от бутончето в ляво избираш "Send...", също както е показано.
-
Понеже вече в традиционните библиотеки има и създадени електронни каталози,с цел пълноценното използване на фондовете им,предлагам на Назъров да разгледа някои от тях.За изработването на примерната картичка за нашия каталог съм се ръководела от тях.
Не само съм разглеждал някои от тях, но и някои от тях са създадени от мен (например тази на библиотеката на БНР и "златен фонд" на БНР). Точно затова знам, че този подход не е най-подходящият за нашите цели, защото ние не правим електронен каталог на конвенционална библиотека. Или поне аз така си мисля, но може да се окаже и че греша. Какво искаме да направим всъщност?
-
За обикновен потребител каталожната картичка на книгата дори е по-важна и полезна от тази на беседата. Така потребителят преценя какво е съдържанието на книгата и решава дали тя му е необходима в момента. Спестява се време и досадна за един читател последователност от опити и грешки, които сега са неизбежни.
Ама Донке,
Ние не правим традиционна библиотека с физически книги, а електронна. Съответно и технологиите и цялата логика на работа и на ползване от потребителите са много различни, а ми се струва, че вие не виждате ясно разликите.
-
Но когато започнахме да подготвяме каталожните картички за беседите, се сблъскахме с линка за книгите, в които е била публикувана тази беседа. Оказа се, че някои беседи са били включвани в различни книги, издавани по различно време.
Този информационен проблем се решава по следния начин. Създават се два независими един от друг каталога - на беседи и на книги. След това между тях може да бъде създаден междинен каталог, който да ги свърже. Така, от една страна, за всяка беседа ще има списък с книгите, в които е била публикувана, а от друга, за всяка книга ще има списък на включените в нея беседи. Това са тривиални задачи в сферата на информационните технологии, но те се решават най-ефективно посредством релационни бази данни и специализиран потребителски интерфейс. Не знам, каква точно ви е идеята за тези каталожни картички и как те ще бъдат ползвани от потребителите?
-
Уики - методологични стъпки за работа, обсъждане на средствата и стъпките
обсъждане на средствата и стъпките
Здравейте, приятели!
да споделя няколко идеи относно средствата и процедурите за работа. Можем да използване описаната по-долу структура като скелет, към който да добавяме нови и да усъвършенстваме действащите процедури.
1. Качване на нова сканирана книга във уикито.
1.1. Качването се прави в раздел "Книги, по които се работи", при което се описва и съдържанието (стр. и заглавие на беседите).
1.2. Пуска се обявява за "нова книга за работа" в работния форум.
1.3. След съдържанието може да се опишат допълни изисквания от организационен характер, като крайна дата, до която книгата е желателно да бъде готова и т.н.
2. Взимане (резервиране) на беседа за работа.
2.1. Преди да се вземе (резервира) нова беседа, трябва да се провери дали в нея има таблици, схеми, бележки под черта или други елементи, които изискват по-сложна обработка. Така доброволецът трябва да прецени дали обработката на тази беседа е в неговите възможности и ако не, да избере друга беседа.
2.2. Резервирането става като се редактира заглавието на беседата в описа на съдържанието, като след заглавието на беседата се пише: "(Потребителски акаунт) (Работи се)".
2.3. С взимането (резервирането) на беседата, доброволецът се ангажира да я обработи до крайния срок обявен за книгата. Ако след взимането на беседата доброволецът разбере че е възпрепятстван да я обработи в срок, следва да я обяви своевременно в работния форум (или да я върне, ако нищо не е работил по нея), за да може тя да бъде поета/продължена от друг доброволец.
3. Работа по взета беседа.
3.1. Създава се нов текстов документ (в .RTF формат) за беседата и се отваря в предпочитания от оператора текстов редактор. Препоръчително е да се работи с редактор, който има корекция на правопис.
3.2. Тук следва да се добави спецификация на стандартите за форматиране и редакция на текста, които предстои да бъдат уточнени. Трябва да се специфицират също и правилните настройки на програмата ABBYY Fine Reader.
3.3. Отваря се сканираната книга (PDF) с програмата ABBYY Fine Reader. (Забележка: Моят опит показва, че е най-ефективно и лесно грубата корекция на стария правопис да се прави намясто след разпознаването. Така, успоредно с грубата корекция се прави и сверка с оригинала, което в много случаи спомага за предотвратяване на грешки при корекцията, форматирането и обработката на схеми, диаграми, бележки под черта и т.н.)
3.3.1. Избира се Thumbnail-а на сканираното изображение на първата страница от беседата и с чукване на десния бутон на мишката върху него се избира "Read Page". След завършване на разпознаването в десния прозорец имаме текстов редактор с разпознатия текст на текущо избраната страница.
3.3.2. Коригира се текста според стандартите от т.3.2.
3.3.2.1. Копира се коригирания текст и се поставя в отворения текстов редактор (т.3.1.). Обработват се схеми, диаграми, бележки под линия и др. (ако има такива) и се вмъкват на съответните места в текста.
3.3.2.2. Прави се финален прочит/преглед на страницата, вече в текстовия редактор и се запаметяват промените. Тук, в зависимост от нивото на редакторска компетентност на доброволеца, може да се направи и по-фина степен на редакция.
3.3.2.3. Ако работата трябва да бъде преустановена и продължена друг път, на нов ред се записва номера на следващата страница, която трябва да бъде добавена. Така, при възобновяване на работата ще е ясно от къде трябва да се продължи.
3.3.2.4. Повтаря се горната процедура поотделно за всички страници на беседата.
3.3.2.5. Прави се финален прочит/преглед на цялата беседа и се запазват промените. С това корекцията е завършена.
4. Депозиране на обработена беседа.
4.1. Копира се готовия текст на беседата от текстовия редактор и се поставя на съответното място в уикито.
4.1.1. Тук следва да се специфицират необходимите допълнителни операции за поставяне на графики, таблици, диаграми, бележки под черта и т.н. Също за форматиране на заглавието, новите редове и други.
4.1.2. Редактира се заглавието на беседата в описа на съдържанието, като след заглавието на беседата се пише: "(Потребителски акаунт) (Ниво на редакция)".
4.2. При депозиране на беседа с годно за публикация ниво на редакция, тя трябва бъде публикувана за свободно ползване.
Следва продължение...
-
В тази тема ще се опитам да дам най-общи правила при създаването на една каталожна картичка с оглед на информацията,която ни трябва за създаването на каталога на Словото.
Здравей, Моника!
Според както аз виждам целите на проекта, нашата задача е да направим електронен архив и на първо място да каталогизираме словото така, както то е било изнасяно, в неговия изворов вид, а чак на второ и трето място можем да каталогизираме и различните печатни издания.
В този смисъл, за най-базова единица в тъканта на словото ние приемаме беседата. От тук естествено следва и най-базовият архивен каталог на словото - хронологичен - по дата, час и място на изнасяне, а също и вид на беседата (Неделни беседи; Лекции – общ клас; Лекции – специален клас; Утринни слова; Съборни беседи; Младежки събори; Беседи при Седемте рилски езера; Беседи на сестрите; Беседи на ръководителите; Беседи класа на добродетелите; Извънредни беседи; Разговори с ученици; Музика и т.н.). Това аз виждам като нашата първостепенна задача - събиране, електронизиране, картотекиране и осигуряване на свободен достъп до цялото слово в неговия автентичен, изворов вид.
Като втора задача, вече върху основата на този архив, могат да бъдат надграждани допълнителни справочни каталози като например: каталог на печатните издания; каталог на електронните публикации; каталог на притчите в словото, тематичен указател и т.н. и т.н.
Като трета задача, отделно от архива и каталозите на самото слово на Учителя, може да се направят и допълнителни архиви и каталози на статии, книги, филми, музика и най-общо казано - материали от трети автори за словото и Учителя.
Какво мислите вие, приятели?
-
Ето няколко интересни и потенциално полезни разширения:
Прегледал съм само до края на буквата "C". По-късно ще продължа нататък.
-
Също Васко (ник: Васил) ми писа днес, че трябва да се включи възможността за качване на картинки. В някои от беседите има такива.
Да, и аз не успях да кача, но мислех, че е нещо от правата.
-
Друг важен въпрос е какво ще правим с бележките под черта. Възможно решение: Extension:Cite в комбинация с Extension:Word2MediaWikiPlus
Книжарницата. Отзиви
в За Книжарницата
Добавено
Здравейте, приятели!
Поздравления за тази чудесна услуга към Портала.
Поръчах 3 книги по обед и ги получих още в същия ден, няколко часа по-късно.
Благодаря и успех!
--
Васил Назъров